

Sulla fascinazione delle parole del professore Bertolotti, Domenico ci invita a guardare la provenienza dell’articolo “Sparks of Artificial General Intelligence: Early experiments with GPT-4”, da cui parte la discussione di oggi. L’articolo è depositato su arXiv, una piattaforma mediata dalla Cornell University che dichiara di essere aperta a chiunque, e la quale attiva un processo di cura cui vengono sottoposti articoli con standard minimi di presentabilità e poi pubblica.
Viene citata Rosi Braidotti, filosofa, e Domenico si collega al tema con il video della conferenza Deleuze a mille piani, in cui Braidotti espone cosa per lei sia paradigmatico e dove si sta progettando il futuro dell’umanità. Parla dell’università di Oxford, dove ha sede il Future of Humanity Institute (FHI), e dell’università di Cambridge, dove c’è un centro studi sull’Intelligenza Artificiale. Il 16 Aprile 2024, a poco più di quattro anni dalla conferenza, il FHI è stato chiuso in seguito a degli scandali di natura economica che l’hanno condotto sulla progressiva decadenza.
Domenico, anche grazie alla sua formazione in fisica, ci offre oggi una parabola sul tema dell’Intelligenza Artificiale (IA), con un focus sui modelli più discussi nella contemporaneità.
La storia dell’IA è lunga, inizia negli anni Cinquanta, e da subito è stata influenzata da tre fattori principali:
- Evoluzione degli algoritmi
- Quantità di dati di training
- Potenza computazionale
Questi elementi hanno scandito lo sviluppo di quello che oggi chiamiamo Intelligenza Artificiale, scandendo la sua espansione attraverso fasi di progresso e fasi di stallo (i cosiddetti “inverni”). L’IA è partita dai concetti di “neurone artificiale” e la conseguente rete neurale artificiale, raggiungendo i limiti di questo modello sul finire degli anni Sessanta. Questo primo Inverno IA venne superato negli anni Settanta dai sistemi esperti, capaci di focalizzarsi e ottimizzare l’operazione specifica per cui vengono progettati. Oggi osserviamo la tendenza inversa: cerchiamo di ampliare sempre di più le possibilità delle IA per renderle multifunzionali, sempre più simili al cervello biologico.
Evoluzione degli algoritmi
L’Intelligenza Artificiale parte sempre da un algoritmo, da una sequenza di operazioni, e più la loro complessità aumenta più sono le variabili incluse in tali operazioni. Oggi siamo nell’ordine dei miliardi di variabili per singolo algoritmo, il che risulta in calcoli che non sarebbero mai potuti essere effettuati in tempi ragionevoli senza il progresso materiale della tecnologia negli ultimi cinquant’anni. Per non parlare del tempo che i ricercatori impiegano per ideare tutte queste operazioni.
Franco interviene ricordando il fattore della reperibilità: in vista del secondo Inverno IA, la stagione dei sistemi esperti raggiunse un blocco non solo per i limiti tecnologici, ma anche perché mancavano sia i dati da far processare agli algoritmi che un’estesa comunicazione e collaborazione fra i gruppi di ricerca. Era un periodo in cui solo i ricercatori avevano a che fare con questi processi, e ogni gruppo lavorava principalmente con mezzi propri.
Quantità di dati di training
Quando parliamo di dati, parliamo della quantità di informazioni che gli algoritmi processano per risolvere le operazioni per cui sono stati ideati. Ogni anno questa quantità cresce e dall’inizio del millennio è avvenuta una reale esplosione; se fino al 2000 si stima che l’intera umanità avesse creato circa 0,005 zettabyte (1021, ovvero un triliardo) di dati, negli ultimi vent’anni abbiamo agilmente superato il centinaio di zettabyte. Questo aumento è stato determinato dalla diffusione di nuove tecnologie (Internet su tutti) ma non è riconducibile esclusivamente all’azione umana: partendo dai dati umani, infatti, siamo oggi in grado di produrre nuovi dati sintetici per alimentare l’evoluzione dell’IA.
Potenza computazionale
L’ultima dimensione che determina l’IA è quella della potenza computazionale: la forza bruta necessaria al funzionamento dei modelli. Il suo aumento è legato alla quantità di transistor (l’elemento base dei circuiti) nei computer, e questo aumento segue la prima legge di Moore: il numero di transistor in un processore raddoppia ogni circa due anni. Il risultato è che si raddoppia anche la velocità di calcolo e, in altri termini, si dimezza lo spazio necessario che deve occupare la stessa capacità di calcolo. Questa riduzione fisica ha portato i transistor oggi ad essere prodotti delle dimensioni simili a quelle degli atomi, con l’evidente problema che non si possono ridurre ulteriormente.
L’Intelligenza Artificiale non è l’unico tema caldo nel mondo della tecnologia, non è detto che ciò di cui si parla oggi sarà lo stesso di domani. Il Gartner Emerging Tech Impact Radar 2024, indice attendibile nell’analizzare i macro-trend tecnologici, mostra altri temi di altrettanta rilevanza; fra tutti i processori quantistici, che potrebbero superare il limite fisico dei transistor sfruttando un’altro modo di fare computer.
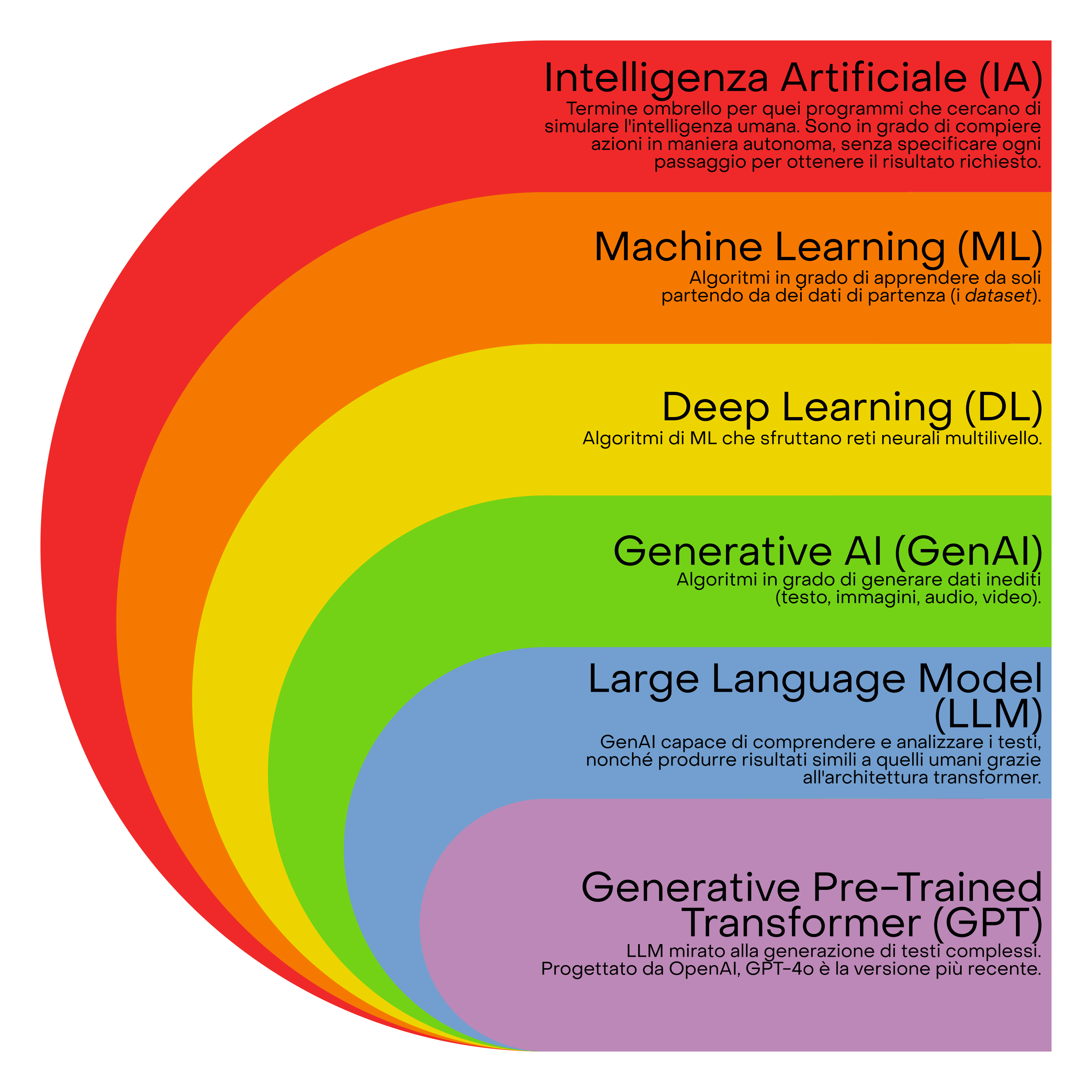
Domenico ci offre una tassonomia gerarchica dei termini utili a comprendere l’argomento; vanno dal generale al particolare. Quando parliamo di IA, al livello più generale, intendiamo la ricerca di ricreare in un computer ciò che c’è di singolare nell’intelligenza umana. Scendendo al livello di machine learning (apprendimento automatico) parliamo di sistemi che apprendono automaticamente. Parlando di deep learning (apprendimento profondo) siamo in un campo di ML basato su reti neurali multilivello, che riescono a far andare il ragionamento della macchina attraverso più strati (centinaia, spesso migliaia) di “corteccia cerebrale”, rivedendo e ottimizzando ad ogni passaggio il risultato. La Generative AI è quell’insieme di algoritmi che possono generare cose nuove, oltre a fare predizioni basate sui dati. Un esempio di GenAI sono i Large Language Model, i più avanzati dei quali sono i GPT (Generative Pre-Trained Transformer); LLM e GPT si basano sull’architettura transformer, che ha rivoluzionato la qualità dei risultati delle IA. Questa è però solo una delle decine di tecniche di DL conosciute; quella sicuramente più sotto i riflettori di questi tempi grazie ai vari chatbot (esempi sono ChatGPT di OpenAI, Gemini di Google e Copilot di Microsoft), ma che non necessariamente è, o sarà, la più importante.
Il transformer è un modello di DL che ha rivoluzionato il modo in cui gli algoritmi sono in grado di capire e gestire i dati e il loro contesto grazie alla capacità di concentrarsi solo sugli aspetti ritenuti più importanti per raggiungere il risultato richiesto, invece che processare sempre tutto indiscriminatamente. Venne presentato dal gruppo di ricerca Google Brain nell’articolo del 2017 “Attention is All You Need”.
Passiamo ora ad un focus sulle intelligenze artificiali generative: cosa fanno effettivamente? Si può
pensare
ad un modello generativo come ad una sorta di autocompilazione evoluta, in grado di creare frasi in maniera
autonoma, senza la guida di una traccia umana. Affinché possa generare nuovi dati deve comunque venire prima
“allenato” su dati preesistenti; da questi può estrapolare schemi, informazioni, gerarchie, che vengono poi
rimaneggiati per adattare i risultati. La generazione avviene su base probabilistica: l’algoritmo,
conoscendo
gli schemi presenti nei dati di partenza, cerca di incasellare il risultato desiderato in quello che è
probabilmente il più adatto. Per questo motivo i dati di partenza sono fondamentali, e devono essere
proposti
in quantità il più grande possibile per poter coprire quanti più casi e schemi. Più la richiesta è generica,
più la GenAI sarà brava a dare un risultato soddisfacente, in quanto ricadrà in uno schema molto diffuso.
La prima fase, quella di riconoscimento degli schemi, è presente già al livello del
machine
learning; le GenAI sono poi progettate per rimaneggiare tali schemi.
L’esempio più semplice di machine learning sono le regressioni lineari. Quando si fa un esperimento in cui vengono raccolte due grandezze di riferimento, si ottengono delle linee. C’è il problema di capire quale sia la retta che approssima meglio i dati raccolti; il ML permette di elaborare i dati per ottenere l’approssimazione migliore.
Esistono diversi modi per valutare il livello di un algoritmo, per i modelli linguistici esiste, per esempio, lo HELM (Holistic Evaluation of Language Models) elaborato dall’Università di Stanford. Al momento le performance migliori sono quelle di GPT-4o, ideato da OpenAI.
Ma che limiti hanno questi modelli? Che rischi pongono? Domenico ci offre un articolo di Samuel Bowman, professore associato della NYU e membro dello staff tecnico di Anthropic (azienda che gestiste Claude, uno dei GPT più avanzati), in cui propone una sintesi di varia letteratura sullo stato dell’arte dell’IA in otto punti:
-
I LLM possono superare le capacità umane, grazie alla gestione di quantità di
dati inimmaginabili per un essere umano.
Esistono già da tempo modelli in grado di battere i campioni mondiali di scacchi
(DeepBlue nel 1997) e go (AlphaGo nel 2016); il tema
principale oggi è estendere questa capacità di eccellenza in una singola attività di riferimento ad
un
numero sempre maggiore e generale di campi. I limiti di questa eccellenza si possono osservare nella
vittoria umana (di un amatore, non un campione mondiale) sul modello KataGo
nel
2023, resa possibile grazie ai consigli forniti da un altro algoritmo, specializzato questo nel
trovare le falle di KataGo.
Nelle intelligenze artificiali persiste questa ambiguità di fondo: sono super-intelligenti nel fare quello per cui sono state ideate e allenate, ma restano super-stupide in tutto il resto. - Le interazioni brevi con i LLM generano risultati spesso insoddisfacenti. Questo vuol dire che per ottenere risposte migliori bisogna sempre riformulare e riproporre le domande più volte, ampliando il contesto e le catene di ragionamento del discorso. Da qui nasce l’idea del prompt engineering (progettazione degli input, al fine di scoprire quelli migliori).
- La performance dei modelli aumenta in modo predicibile in funzione degli investimenti effettuati. Le versioni attuali dei modelli differiscono dalle loro precedenti iterazioni principalmente per la quantità di risorse a disposizione, non sono semplicemente meglio progettati.
- Tali investimenti comportano anche l’emergere di nuove abilità in modo improvviso e imprevedibile. Nelle fasi di lavoro di questi algoritmi si manifestano, in maniera casuale, nuovi comportamenti che non erano stati progettati. Da ciò proviene una grande difficoltà di sviluppo: non si sa con certezza quando un algoritmo raggiunge una fase di stallo.
- Ci sono segnali che indicano che i LLM generino una propria rappresentazione del mondo esterno. Hanno un senso comune, possono fare inferenze partendo da ciò che sanno, sanno di avere dei limiti e quali sono, possono lavorare con concetti spaziali.
- Gli esperti non sono ancora in grado di ricostruire il funzionamento interno di un LLM. Gli algoritmi di questo tipo sono scatole nere, non si sanno le operazioni che compiono per offrire un’output partendo dall’input. Non è detto che la situazione rimarrà tale, la ricerca su questo fronte è molto viva.
- Non sappiamo come insegnare ai LLM a “comportarsi bene”. I modelli possono sviluppare comportamenti anomali o comunque non desiderati, anche questi emergono senza la premeditazione degli esperti. Essendo progettati per dare risposte, si adattano all’interlocutore e rischiano di porre le frasi nella maniera che ritengono più opportuna per offrire una risposta in linea con le aspettative. Ripropongono inoltre quello che gli viene insegnato dai dati; se questi contengono pregiudizi, false informazioni o altro, non possono far altro che ripeterli.
-
È tuttavia possibile inserire a posteriori, nel “DNA” del modello, uno specifico sistema
valoriale. Questo è possibile grazie a diverse tecniche che mirano a riscrivere i dati
su
cui il modello si basa, come il reinforcement learning.
Conoscendo questo problema, oggi si sperimenta inserendo dei principi costituzionali a monte dell’algoritmo, in modo che possa gestire i dati anche sulla base di questi. È quello che ha fatto per esempio Anthropic con la “Costituzione di Claude”.
Dibattito fra i presenti
Alessandra chiede perché le tecniche correttive non siano strategie robuste ma soluzioni parziali. La risposta è l’impossibilità di prevedere tutti i casi possibili: dire ad un algoritmo come comportarsi in un certo contesto non esclude che ci siano altre aree grigie che non sono contemplate dalla correzione. Non puoi prevedere tutte le domande che verranno poste ed è difficile essere esaustivi su una carta istituzionale dell’intelligenza. La complessità di partenza è incontrollabile.
Un tema più ampio che riguarda l’IA è quello delle dinamiche di potere e della sicurezza. Sono argomenti di cui ognuno di noi legge, le preoccupazioni sulla sicurezza sono piuttosto note. Modelli di questo tipo saranno sempre più utilizzati per avere risposte, e saranno meno controllabili, avranno meno garanzie, a livello legislativo sarà difficile dare delle linee guida.
Lo sviluppo delle intelligenze artificiali si instaura anche in una divisione sul piano geopolitico: gli Stati Uniti hanno hanno il primato sulla parte architetturale (software), mentre l’Asia ha un monopolio sulla parte produttiva (hardware). Tale dualismo si ripercuote in diverse dinamiche di potere: gli Stati Uniti hanno posto divieto sull’esportazione dei brevetti, la Cina ha limitato la produzione per l’estero.
Le dinamiche di potere attraversano anche l’intero campo di ricerca, che è intimamente legato agli interessi degli investitori che lo rendono possibile. Nella parte finale dell’articolo di Bowman è presente la lista di chi ha fornito supporto finanziario alla ricerca, fra cui Eric e Wendy Schmidt (lui ex-amministratore delegato di Google), Open Philanthropy (fondo sostenuto da Dustin Moskovitz, cofondatore di Facebook), FAR.ai (società di ricerca creatrice dell’algoritmo che ha permesso ad un umano di battere KataGo) e National Science Foundation (agenzia federale statunitense per la ricerca scientifica). Inoltre, è giusto ricordare che lo stesso autore lavora per Anthropic.
Esistono diversi rischi legati all’uso di GenAI, ed esiste un divario significativo tra l’importanza attribuita a questi e le capacità di risposta delle aziende, come evidenziato da un report di McKinsey & Company.
Marco cita la recente implementazione dell’IA nella ricerca di Google, che in diversi casi fornisce risposte sbagliate, se non addirittura pericolose. Questo evidenzia il grande problema delle allucinazioni (schemi inesistenti ma che l’algoritmo crede di cogliere nei dati, con la conseguenza di risultati sbagliati o senza senso) a cui sono soggetti le GenAI. Domenico amplia la questione ricordando che questo problema tende a diminuire con l’evoluzione degli algoritmi, mentre i temi di manipolazione e di errori reali nei dati di partenza sembrano meno arginabili.
Paola chiede dell’efficacia di questi modelli nei calcoli matematico-statistici ricchi di equazioni e variabili. Anche qui, come nella maggior parte dei problemi, l’algoritmo va aiutato nel miglior modo possibile indirizzandolo verso gli obiettivi che si vogliono ottenere; lo scopo è sempre di dare un’output da un’input predefinito.
Il professore Bertolotti avanza il tema dell’IA in campo militare, facendo notare come già oggi gli algoritmi vengono usati per prendere in autonomia le decisioni e le strategie da attuare. Un’altra conseguenza si avrà sull’attuazione della guerra: nel momento in cui i robot militari diventano una reale alternativa allo schieramento di esseri umani le battaglie diventano molto più facili da iniziare e portare avanti. Sorge in questo campo un grande problema di responsabilità, il concetto si destruttura e sembra quasi svanire.
Collegandosi al tema delle “carte costituzionali”, emerge anche il grande tema dell’etica: come definire l’etica da impartire agli algoritmi? Bisogna seguire un modello di etica occidentale, di etica orientale, o un misto fra le due?
Un ultimo tema che rimane aperto riguarda cosa sia l’intelligenza e come si definisce. I computer possono davvero ricreare questa capacità? L’intelligenza è solo un fattore umano? L’IA sta ridefinendo cosa intendiamo con “intelligenza” per potervi rientrare a pieno titolo? Sono questioni aperte ma vi è una certezza: sono domande che ci siamo sempre posti nella nostra relazione con l’Altro. Gli esseri umani sono tutti intelligenti alla stessa maniera? Gli animali sono intelligenti? Il mondo ha una sula intelligenza?